The past ten years have seen dramatic advances in AI driven by huge computational, human, and fiscal resources. Many narrow AI applications are better than humans at their assigned tasks, and are certainly far faster and cheaper.31 And there are also narrow super-human agents that can trounce all people at narrow-domain games such as Go, Chess, and Poker, as well as more general agents that can plan and execute actions in simplified simulated environments as effectively as humans can.
Most prominently, current general AI systems from OpenAI/Microsoft, Google/Deepmind, Anthropic/Amazon, Facebook/Meta, X.ai/Tesla and others32 have emerged since early 2023 and steadily (though unevenly) increased their capabilities since then. All of these have been created via token-prediction on huge text and multimedia datasets, combined with extensive reinforcement feedback from humans and other AI systems. Some of them also include extensive tool and scaffold systems.
Strengths and weaknesses of current general systems
These systems perform well across an increasingly broad range of tests designed to measure intelligence and expertise, with progress that has surprised even experts in the field:
- When first released, GPT-4 matched or exceeded typical human performance on standard academic tests including SATs, GRE, entrance exams, and bar exams. More recent models likely perform significantly better, though results are not publicly available.
- The Turing test – long considered a key benchmark for “true” AI – is now routinely passed in some forms by modern language models, both informally and in formal studies.33
- On the comprehensive MMLU benchmark spanning 57 academic subjects, recent models achieve domain-expert level scores ( ∼ 90%)34
- Technical expertise has advanced dramatically: The GPQA benchmark of graduate-level physics saw performance jump from near-random guessing (GPT-4, 2022) to expert level (o1-preview, 2024).
- Even tests specifically designed to be AI-resistant are falling: OpenAI’s O3 reportedly solves the ARC-AGI abstract problem-solving benchmark at human level, achieves top-expert coding performance, and scores 25% on Epoch AI’s “frontier math” problems designed to challenge elite mathematicians.35
- The trend is so clear that MMLU’s developer has now created “Humanity’s Last Exam” – an ominous name reflecting the possibility that AI will soon surpass human performance on any meaningful test. As of writing this, there are claims of AI systems achieving 27% (according to Sam Altman) and 35% (according to this paper) on this extremely difficult exam. It is quite unlikely that any individual human could do so.
Despite these impressive numbers (and their obvious intelligence when one interacts with them)36 there are many things (at least the released versions of) these neural networks cannot do. Currently most are disembodied – existing only on servers – and process at most text, sound and still images (but not video.) Crucially, most cannot carry out complex planned activities requiring high accuracy.37 And there are a number of other qualities strong in high-level human cognition currently low in released AI systems.
The following table lists a number of these, based on mid-2024 AI systems such as GPT-4o, Claude 3.5 Sonnet, and Google Gemini 1.5.38 The key question for how rapidly general AI will become more powerful is: to what degree will just doing more of the same produce results, versus adding additional but known techniques, versus developing or implementing really new AI research directions. My own predictions for this are given in the table, in terms of how likely each of these scenarios is to get that capability to and beyond human level.
| Capability | Description of capability | Status/prognosis | Scaling/known/new |
|---|---|---|---|
| Core Cognitive Capabilities | |||
| Reasoning | People can do accurate, multistep reasoning, following rules and checking accuracy. | Dramatic recent progress using extended chain-of-thought and retraining | 95/5/5 |
| Planning | People exhibit long-term and hierarchical planning. | Improving with scale; can be strongly aided using scaffolding and better training techniques. | 10/85/5 |
| Truth-grounding | GPAIs confabulate ungrounded information to satisfy queries. | Improving with scale; calibration data available within model; can be checked/improved via scaffolding. | 30/65/5 |
| Flexible problem-solving | Humans can recognize new patterns and invent new solutions to complex problems; current ML models struggle. | Improves with scale but weakly; may be solvable with neurosymbolic or generalized “search” techniques. | 15/75/10 |
| Learning and Knowledge | |||
| Learning & memory | People have working, short-term, and long-term memory, all of which are dynamic and inter-related. | All models learn during training; GPAIs learn within context window and during fine-tuning; “continual learning” and other techniques exist but not yet integrated into large GPAIs. | 5/80/15 |
| Abstraction & recursion | People can map and transfer relation sets into more abstract ones for reasoning and manipulation, including recursive “meta” reasoning. | Weakly improving with scale; could emerge in neurosymbolic systems. | 30/50/20 |
| World model(s) | People have and continually update a predictive world model within which they can solve problems and do physical reasoning | Improving with scale; updating tied to learning; GPAIS weak in real-world prediction. | 20/50/30 |
| Self and Agency | |||
| Agency | People can take actions in order to pursue goals, based on planning/prediction. | Many ML systems are agentic; LLMs can be made agents via wrappers. | 5/90/5 |
| Self-direction | People develop and pursue their own goals, with internally-generated motivation and drive. | Largely composed of agency plus originality; likely to emerge in complex agential systems with abstract goals. | 40/45/15 |
| Self-reference | People understand and reason about themselves as situated within an environment/context. | Improving with scale and could be augmented with training reward. | 70/15/15 |
| Self-awareness | People have knowledge of and can reason regarding their own thoughts and mental states. | Exists in some sense in GPAIs, which can arguably pass the classic “mirror test” for self-awareness. Can be improved with scaffolding; but unclear if this is enough. | 20/55/25 |
| Interface and Environment | |||
| Embodied intelligence | People understand and actively interact with their real-world environment. | Reinforcement learning works well in simulated and real-world (robotic) environments and can be integrated into multimodal transformers. | 5/85/10 |
| Multi-sense processing | People integrate and real-time process visual, audio, and other sensory streams. | Training in multiple modalities appears to “just work,” and improve with scale. Realtime video processing is difficult but e.g. self-driving systems are rapidly improving. | 30/60/10 |
| Higher-order Capabilities | |||
| Originality | Current ML models are creative in transforming and combining existing ideas/works, but people can build new frameworks and structures, sometimes tied to their identity. | Can be hard to discern from “creativity,” which may scale into it; may emerge from creativity plus self-awareness. | 50/40/10 |
| Sentience | People experience qualia; these can be positive, negative or neutral valence; it is “like something” to be a person. | Very difficult and philosophically fraught to determine whether a given system has this. | 5/10/85 |
Breaking down what is “missing” in this way makes it fairly clear that we are quite on-track for broadly above-human intelligence by scaling existing or known techniques.39
There could still be surprises. Even putting aside “sentience,” there could be some of the listed core cognitive capabilities that really can’t be done with current techniques and require new ones. But consider this. The present effort being put forth by many of the world’s largest companies amounts to multiple times the Apollo project’s and tens of times the Manhattan project’s spend,40 and is employing thousands of the very top technical people at unheard of salaries. The dynamics of the past few years have now brought to bear more human intellectual firepower (with AI now being added) to this than any endeavor in history. We should not bet on failure.
The big target: generalist autonomous agents
The development of general AI over the past several years has focused on creating general and powerful but tool-like AI: it functions primarily as a (fairly) loyal assistant, and generally does not take actions on its own. This is partly by design, but largely because these systems have simply not been competent enough at the relevant skills to be entrusted with complex actions.41
AI companies and researchers are, however, increasing shifting focus toward autonomous expert-level general-purpose agents.42 This would allow the systems to act more like a human assistant to which the user can delegate real actions.43 What will that take? A number of the capabilities in the “what’s missing” table are implicated, including strong truth-grounding, learning and memory, abstraction and recursion, and world-modeling (for intelligence), planning, agency, originality, self-direction, self-reference, and self-awareness (for autonomy), and multi-sense-processing, embodied intelligence, and flexible problem-solving (for generality).44
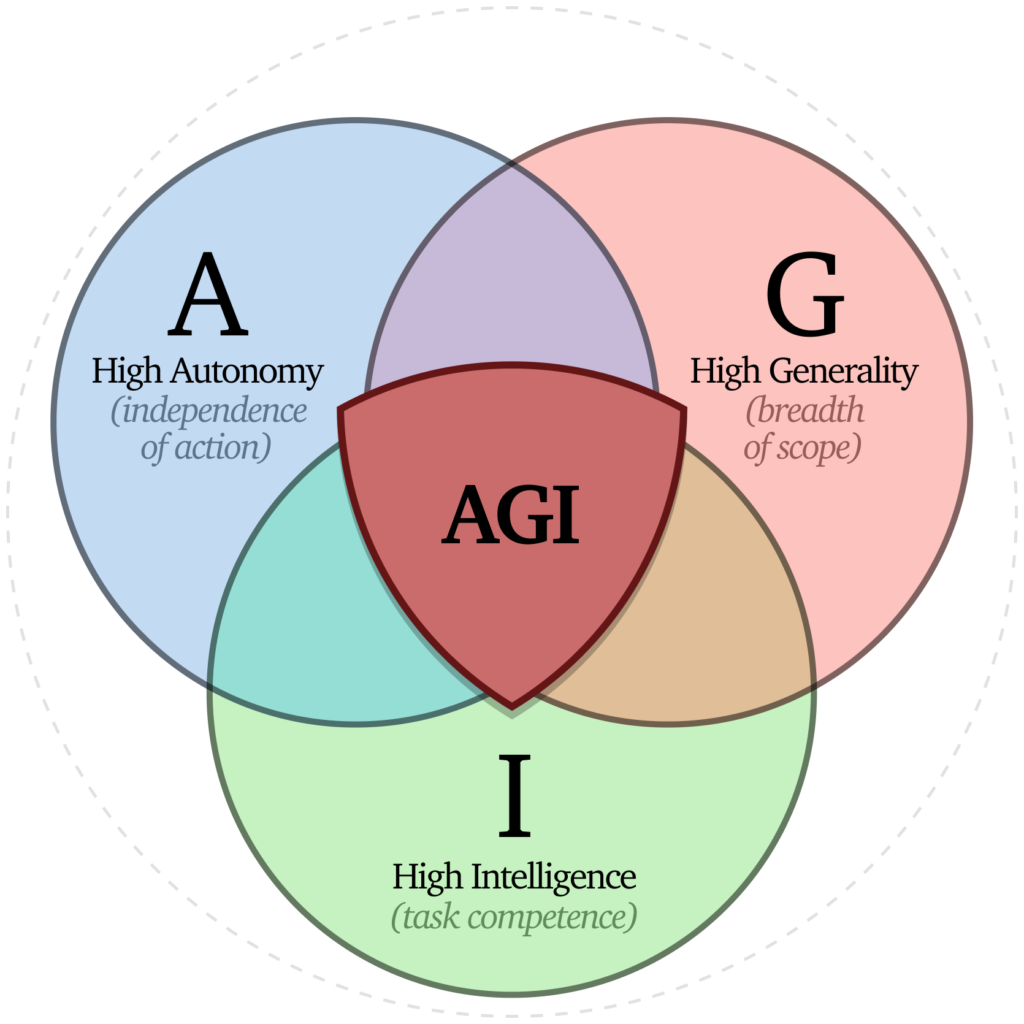
This triple-intersection of high autonomy (independence of action), high generality (scope and task breadth) and high intelligence (competence at cognitive tasks) is currently unique to humans. It is implicitly what many probably have in mind when they think of AGI – both in terms of its value as well as its risks.
This provides another way to define A-G-I as Autonomous-General-Intelligence, and we’ll see that this triple intersection provides a very valuable lens for high-capability systems both in understanding their risks and rewards, and in governance of AI.
The AI (self-)improvement cycle
A final crucial factor in understanding AI progress is AI’s unique technological feedback loop. In developing AI, success – in both demonstrated systems and deployed products – brings additional investment, talent, and competition, and we are currently in the midst of an enormous AI hype-plus-reality feedback loop that is driving hundreds of billions, or even trillions, of dollars in investment.
This type of feedback cycle could happen with any technology, and we’ve seen it in many, where market success begets investment, which begets improvement and better market success. But AI development goes further, in that now AI systems are helping to develop new and more powerful AI systems.45 We can think of this feedback loop in five stages, each with a shorter timescale than the last, as shown in the table.
| Stage | Timescale | Key Drivers | Current Status | Rate-Limiting Factors |
|---|---|---|---|---|
| Infrastructure | Years | AI success → investment → better hardware/infrastructure | Ongoing; massive investment | Hardware development cycle |
| Model Development | 1-2 Years | Human-led research with AI assistance | Active across major labs | Training run complexity |
| Data Generation | Months | AI systems generating synthetic training data | Beginning phase | Data quality verification |
| Tool Development | Days-Weeks | AI systems creating their own scaffolding/tools | Early experiments | Software integration time |
| Network Self-Improvement | Hours-weeks | Groups of AI systems innovate “social” institutions | Unknown | Inference rate |
| Recursive Improvement | Unknown | AGI/superintelligent systems autonomously self-improving | Not yet possible | Unknown/ unpredictable |
Several of these stages are already underway, and a couple clearly getting started. The last stage, in which AI systems autonomously improve themselves, has been a staple of the literature on the risk of very powerful AI systems, and for good reason.46 But it is important to note that it is just the most drastic form of a feedback cycle that has already started and could lead to more surprises in the rapid advancement of the technology.
- You use a lot more of this AI than you probably think, driving speech generation and recognition, image processing, newsfeed algorithms, etc.↩︎
- While relationships between these pairs of companies are quite complex and nuanced, I have explicitly listed them to indicate both the vast overall market capitalization of firms now enjoined in AI development, and also that behind even “smaller” companies like Anthropic sit enormously deep pockets via investments and major partnership deals.↩︎
- It has become fashionable to disparage the Turing test, but it is quite powerful and general. In weak versions it indicates whether typical people interacting with an AI (which is trained to act human) in typical ways for brief periods can tell whether it is an AI. They cannot. Second, a highly adversarial Turing test can probe essentially any element of human capability and intelligence – by e.g. comparing an AI system to a human expert, evaluated by other human experts. There is a sense in which much of AI evaluation is a generalized form of Turing test.↩︎
- This is per domain – no human could plausibly achieve such scores across all subjects simultaneously.↩︎
- These are problems that would take even excellent mathematicians substantial time to solve, if they could solve them at all.↩︎
- If you are of a skeptical bent, retain your skepticism but really take the most current models for a spin, as well as try for yourself some of the test questions they can pass. As a physics professor, I would predict with near certainty that, for example, the top models would pass the graduate qualifying exam in our department.↩︎
- This and other weaknesses like confabulation have slowed market adoption and led to a gap between perceived and claimed capabilities (which must also be viewed through the lens of intense market competition and the need to attract investment.) This has confused both the public and policymakers about the actual state of AI progress. While perhaps not matching the hype, the progress is very real.↩︎
- The major advance since then has been development of systems trained for top-quality reasoning, leveraging more computation during inference and greater reinforcement learning. Because these models are new and their capabilities less tested, I’ve not wholly revamped this table except for “reasoning”, which I regard as essentially solved. But I have updated predictions based on experienced and reported capabilities of those systems.↩︎
- Previous waves of AI optimism in the 1960s and 1980s ended in “AI winters” when promised capabilities failed to materialize. However, the current wave differs fundamentally in having achieved superhuman performance in many domains, backed by massive computational resources and commercial success.↩︎
- The full Apollo project cost about $250bn USD in 2020 dollars, and the Manhattan project less than a tenth that. Goldman Sachs projects a trillion dollars of spend just on AI data centers over the next few years.↩︎
- Although humans make plenty of mistakes, we underestimate just how reliable we can be! Because probabilities multiply, a task requiring 20 steps to do correctly requires each step to be 97% reliable just to get it done right half the time. We do such tasks all the time.↩︎
- A strong move in this direction has very recently been taken with OpenAI’s “Deep Research” assistant that autonomously performs general research, described as “a new agentic capability that conducts multi-step research on the internet for complex tasks.”↩︎
- Things like fill in that pesky PDF form, book flights, etc. But with a PhD in 20 fields! So also: write that thesis for you, negotiate that contract for you, prove that theorem for you, create that ad campaign for you, etc. What do you do? You tell it what to do, of course.↩︎
- Note that sentience is not clearly required, nor does AI in this triple-intersection necessarily imply it.↩︎
- The closest analogy here is perhaps chip technology, where development has maintained Moore’s law for decades, as computer technologies help people design the next generation of chip technology. But AI will be far more direct.↩︎
- It’s important to let it sink in for a moment that AI could – soon – be improving itself on a timescale of days or weeks. Or less. Keep this in mind when someone tells you an AI capability is definitely far away.↩︎